
Abstract
It is possible to create interactive, responsive web applications that allow user-generated contributions. However, the relevant technologies have to be explicitly deployed by the authors of the web pages. In this work we present the concept of parasitic and symbiotic web applications which can be deployed on arbitrary web pages by means of a proxy-based application platform. Such applications are capable of inserting, editing and deleting the content of web pages. We use an HTTP proxy in order to insert JavaScript code on each web page that is delivered from the web server to the browser. Additionally we use a database server hosting user-generated scripts as well as high-level APIs allowing for implementing customized web applications. Our approach is capable of cooperating with existing web pages by using shared standards (e.g. formatting of the structure on DOM level) and common APIs but also allows for user-generated (parasitic) applications on arbitrary web pages without the need for cooperation by the page owner.
F. Alt, A. S. Shirazi, A. Schmidt, and R. Atterer, “Bridging Waiting Times on Web Pages,” in Proceedings of the fourteenth acm sigchi’s international conference on human-computer interaction with mobile devices and services`, New York, NY, USA, 2012. |
F. Alt, A. S. Shirazi, A. Schmidt, and J. Mennenöh, “Increasing the User’s Attention on the Web: Using Implicit Interaction based on Gaze Behavior to Tailor Content,” in Proceedings of the seventh nordic conference on human-computer interaction, New York, NY, USA, 2012. |
To access the application (script) data in the database on the annotation server, the JavaScript which is run inside the browser as a result of the above modifications uses further HTTP requests. XMLHttpRequest objects provide a convenient way of downloading the data. A problem when doing so is that, for security reasons, modern browsers require that the requests are made to the same server which also supplied the original web page. This “same origin” policy is circumvented in the following way: the JavaScript simply makes a request to the same server that the HTML was requested from, which is allowed by the browser. The requested URL is special in that it apparently attempts to access the directory /usaproxylolo/httprequest/ on the server. However, in reality, the request never reaches the original web server. Instead, triggered by the special directory name, it is intercepted by UsaProxy and redirected to the application server, which answers the query and returns the required data.
Bringing Web 2.0 to the Old Web
It is possible to create interactive, responsive web applications that allow user-generated contributions. However, the relevant technologies have to be explicitly deployed by the authors of the web pages. In this work we present the concept of parasitic and symbiotic web applications which can be deployed on arbitrary web pages by means of a proxy-based application platform. Such applications are capable of inserting, editing and deleting the content of web pages. We use an HTTP proxy in order to insert JavaScript code on each web page that is delivered from the web server to the browser. Additionally we use a database server hosting user-generated scripts as well as high-level APIs allowing for implementing customized web applications. Our approach is capable of cooperating with existing web pages by using shared standards (e.g. formatting of the structure on DOM level) and common APIs but also allows for user-generated (parasitic) applications on arbitrary web pages without the need for cooperation by the page owner.
Supported Types of Applications
Especially since the advent of Web 2.0 technology, a lot of research has gone on into the area of automating and customizing web pages based on user-generated code and content. Widely available examples are tools for annotation, adding links, building custom portals, and making alternative queries (see related work). All those tools have in common that they allow users to add content to web pages without any programming knowledge. On a lower level, several approaches allow users to execute their code on arbitrary web pages. Prominent examples are toolkits such as Greasemonkey and WBI or high-level programming languages such as WebL or Chickenfoot.
However those applications have major drawbacks. First, high level applications (such as annotation tools) are static in the sense that they do not allow for customizing or modifying by the user. Second, solutions allowing the deployment of user-generated code are not easily available, since first, the toolkit itself has to be installed as a plug-in which limits its use to certain browsers, and second, the scripts are not centrally available. Finally, existing approaches cannot easily be extended or modified though probably intended by the author, since placing user-generated content requires the use of, e.g., a database. This is difficult due to the same origin policy of modern browsers.
Our system tries to integrate the advantages of different approaches. First, we support pre-implemented applications deployable by users without any programming knowledge. Second, we allow providing applications that can easily be customized, and finally we provide means to implement JavaScript-based applications.
- Static Applications: As mentioned before, a lot of effort has been put into the development of technologies supporting the deployment of applications on top of web pages, hence easing the automation and customization for users. The challenging part for such applications is the storage of data, since web pages are only virtually modified. Most of those applications are static because extending the functionality would require major changes on the provider side and cannot be simply achieved by writing client side code. Yet such applications are very useful, since no programming knowledge is required for their deployment. An example for a static application that can be distributed via an application platform such as the one presented in this work are annotation tools. In chapter 5 we explain how such a system can be integrated with our platform.
- Dynamic Applications:A similar, yet more generic approach is the support of dynamic applications. Although those applications also have to be deployed within the application platform, they leave more space for customization. An example would be an application allowing for generating customized surveys. Connections to external storage such as a database server again have to be implemented within the application platform. Yet the code for the application itself is created dynamically based on user requirements.
- User-implemented applications: Finally we also support applications implemented by users. We provide a module which allows for inserting arbitrary JavaScript code in any web page through the application platform. The JavaScript code is stored in a database and can be fetched and executed on demand. In order to enable users to create dynamic applications, we further provide a simple high-level API realizing access to a database. The API provides methods such as insert(key, value) which writes a (key, value) pair into the database and get(key) which returns the value for a given key. value can be an arbitrary string which allows for storing 2-dimensional data sets. Programmers can simply parse the value variable in order to store multiple attributes. This provides an easy way of avoiding the same origin policy and additionally supports users in creating dynamic applications without the need to care either for XMLHttpRequests or for database connections.
In order to allow the use of the database by multiple applications, we use prefixing for the key values in the form {app1}_{local|global}_key. Hence it is not only possible to use multiple applications but also to determine between local and global entries in the database within one application. Taking the voting system as an example, local entries would be the available options (e.g. votingApp_local_1 = “option 1”), global entries would be the answers of the users (e.g. votingApp_global_1 = “1”).
Parasitic vs. Symbiotic Applications
We now introduce the concept of parasitic and symbiotic applications. In the WWW, the client side has read-only access to web resources. To virtually take control over a web page, pages need to be manipulated directly before or after they are rendered in a browser. Hence an illusion for the users is created pretending that they are given the power to modify a web page itself.
We call a web application parasitic if it is capable of editing, inserting or destroying content on a web page without the need for server side cooperation. We call a web application symbiotic if it uses functionality provided by the server side or provides functionality that can be used by the server side to modify web content. Table 1 gives examples for the different types of applications that become possible with our platform.
Table 1. Classification of parasitic and symbiotic applications.
| Non-cooperative (parasitic) | Cooperative (symbiotic) | |
| Static applications | Annotations tool for arbitrary web pages | Annotation tool supported by web pages using common guidelines |
| Dynamic applications | Voting tool | Customized search tool |
| User-based applications | Script for increasing contrast of web pages | Websites using user-based APIs (e.g. drag and drop) |
Parasitic Applications
Parasitic applications interact with web pages without the explicit permission of the site’s owner. This creates new opportunities since it allows users to adjust web sites to their needs.
While this may sound unattractive at first, parasitic code can be useful in a number of ways: an interested party can increase the accessibility and usability of the web application without having to coordinate this activity with the provider of the application. Furthermore, opposing goals of the application provider and of the users can be solved by users. At the simplest level, this can involve removing advertising, but more controversial changes are also possible, such as preventing users from accidentally signing up for a service they have to pay for. Finally, it is possible to enrich existing applications with new functionality, e.g. by interfacing it with other online services such as maps, dictionaries or even related services of competitors.
Symbiotic Applications
Web pages and applications deployed on top of them can also interact in a symbiotic way. Web page owners can support the use of applications provided by our platform in different ways:
- Page formatting: Repositioning of additional UI elements is not an easy task. Web pages that use identifiers for areas containing text can support applications in a way such that places where insertions or modifications happen can easily be retrieved once the page is loaded, especially if they moved to a different location.
- Provide APIs: Web site owners can provide APIs to be used by applications deployed via the platform. Hence, programmers can be supported and encouraged to write applications, thus increasing the value of a page. Like this, dynamic applications can be supported by providing them access to, e.g., a local database.
Further, page owners can also benefit from deploying platform-based applications:
- Piggyback applications: Page owners can use the APIs provided by the platform to implement applications outside their web server. This allows the use of applications among multiple page owners. An example would be a rating system supported among a company’s web pages. Hence a user-generated rating could be created based on comments and ratings and stored in a third party’s location (in this case the application platform) thus increasing its credibility and liability.
- Increasing usability/functionality: The platform can offer scripts that increase the usability and add functionality to websites by offering tools to the user for customizing and formatting of web pages based on their needs. A simple example would be a script to adjust the font-size according to the users’ preferences.
Implementation
The implemented application platform consists of three components: an HTTP proxy, an application/database server and the client side JavaScript code which supplies the main functionality as well as the user interfaces. Figure 1 gives a simplified overview of the interaction of the components during operation of the application platform.
Application and Database Server
The purpose of the application server is to store the code for both, platform-side applications and for client side JavaScripts in a database, and to retrieve it later upon request. The database is accessible via PHP scripts, which handle storage and retrieval of the data. Furthermore, they pre-process data before returning it to the browser, which simplifies the work of the JavaScript.
Based on the type of modification required by the deployed applications (annotations, voting tools, text marking), different types of information are stored. They can be separated into three classes:
- Content information: data such as the code for creating the voting tool or text that is selected by a marking.
- Positioning information: the topmost positioning information is the URL of the page an application or modification was created for. Additionally, x/y coordinates are stored for relatively positioned content whereas for selections, a string representation of the DOM path, the surrounding context, the actually marked text, and, if available, the ID of the node is stored.
- Additional information: all types of information not directly related to the content or the positioning such as the date a modification was inserted or updated, the author or the title of the page.
Client-side JavaScript
The client-side JavaScript code is inserted into every page by means of the HTTP proxy. Its purpose is to provide the interface for loading and executing available applications from the database. Access to the database is realized using XMLHttpRequest to server-side PHP scripts.
In a similar fashion, the API is made available to programmers using the platform for distributing their applications. The high-level functions that allow programmers to use the platform’s database are written in JavaScript and by default delivered by the proxy by embedding a script tag in the page (script src=”UsaAPI.js”). Further methods can be simply added by updating the remote JavaScript source file. The API would be available immediately for all users hence meeting the requirement of easy maintainability.
Modifications to the Existing Page Layout
Modifications of the original HTML can happen at different granularity levels: The same change (e.g. adding a layer with UI elements) can be performed on all pages of a domain, or it can be tailored for exactly one page on a website. Within pages, the modification can apply to a certain node which must be identified. At the most accurate level, it is specific to individual characters, such as text that has been highlighted by the user.
To be able to implement applications capable of making changes on these levels, different types of information are needed for reinserting the changes correctly on a page. This includes anchor text information and surrounding context as well as structural document information and absolute positioning information. Thus, the platform for deployment of applications supports not only the simple case that absolute positioning is used to add new elements at fixed positions on the page, but also that the positioning depends on the properties of a certain element in the existing document’s Document Object Model (DOM) tree. To allow individual characters to be addressable, e.g. to ensure that an annotation for part of the text appears next to the relevant words, the platform can identify the characters using the offset within their enclosing element. Alternatively, it can store the marked text, i.e. the words or sentences that the user selected when he created the annotation, and employ a substring search at a later time to find it again. This approach can be made more robust against changes on the page by not only storing the marked text, but also some of the text surrounding it.
Bridging Waiting Times on Web Pages
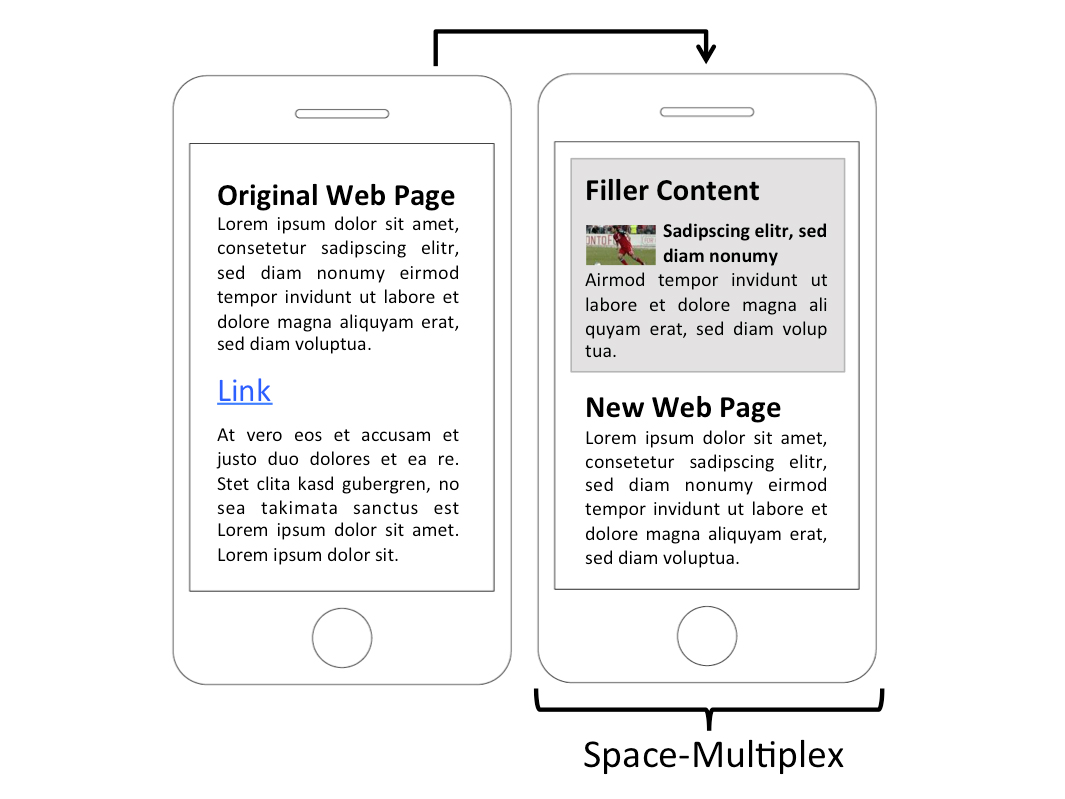
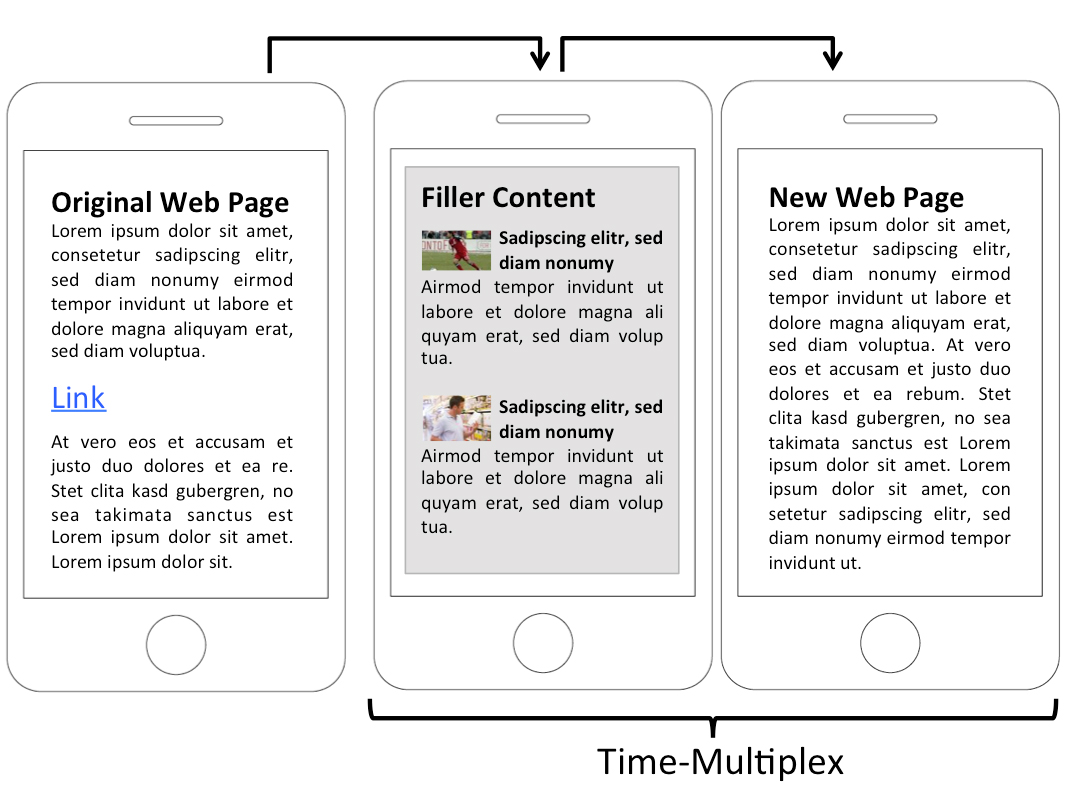
High-speed Internet connectivity makes browsing a convenient task. However, there are many situations in which surfing the web is still slow due to limited bandwidth, slow servers, or complex queries. As a result, loading web pages can take several seconds, making (mobile) browsing cumbersome. We present an approach which makes use of the time spent on waiting for the next page, by bridging the wait with extra cached or preloaded content. We show how the content (e.g., news, Twitter) can be adapted to the user’s interests and to the context of use, hence making mobile surfing more comfortable. We compare two approaches: in time-multiplex mode, the entire screen displays bridging content until the loading is finished. In space-multiplex mode, content is displayed alongside the requested content while it loads. We use an HTTP proxy to intercept requests and add JavaScript code, which allows the bridging content from websites of our choice to be inserted. The approach was evaluated with 15 participants, assessing suitable content and usability.
Increasing User Attention on the Web
The World Wide Web has evolved into a widely used interactive application platform, providing information, products, and services. With eye trackers we envision that gaze information as an additional input channel can be used in the future to adapt and tailor web content (e.g., news, information, ads) towards the users’ attention as they implicitly interact with web pages. We present a novel approach, which allows web content to be customized on-the-fly based on the the user’s gaze behavior (dwell time, duration of fixations, and number of fixations). Our system analyzes the gaze path on a page and uses this information to create adaptive content on subsequent pages. As a proof-of-concept we report on a case study with 12 participants. We presented them both randomly chosen content (baseline) as well as content chosen based on their gaze-behavior. We found a significant increase of attention towards the adapted content and evidence for changes in the user attitude based on the Elaboration Likelihood Model.
Images

Related Publications
F. Alt, A. Schmidt, R. Atterer, and P. Holleis, “Bringing Web 2.0 to the Old Web: A Platform for Parasitic Applications,” in Proceedings of the 12th ifip tc 13 international conference on human-computer interaction: part i, Berlin, Heidelberg, 2009, pp. 405-418. |
F. Alt, A. S. Shirazi, A. Schmidt, and R. Atterer, “Bridging Waiting Times on Web Pages,” in Proceedings of the fourteenth acm sigchi’s international conference on human-computer interaction with mobile devices and services`, New York, NY, USA, 2012. |
F. Alt, A. S. Shirazi, A. Schmidt, and J. Mennenöh, “Increasing the User’s Attention on the Web: Using Implicit Interaction based on Gaze Behavior to Tailor Content,” in Proceedings of the seventh nordic conference on human-computer interaction, New York, NY, USA, 2012. |