Abstract
With computers being used ever more ubiquitously in situations where privacy is important, secure user authentication is a central requirement. Gaze-based graphical passwords are a particularly promising means for shoulder-surfing-resistant authentication, but selecting secure passwords remains challenging. In this paper, we present a novel gaze-based authentication scheme that makes use of cued-recall graphical passwords on a single image. In order to increase password security, our approach uses a computational model of visual attention to mask those areas of the image that are most likely to attract visual attention. We create a realistic threat model for attacks that may occur in public settings, such as filming the user’s interaction while drawing money from an ATM. Based on a 12-participant user study, we show that our approach is significantly more secure than a standard image-based authentication and gaze-based 4-digit PIN entry.
Key Idea
Visual attention is constantly attracted by different parts of the visual scene. Bottom-up computational models of visual saliency aim at estimating the parts of a visual scene that are most likely to attract visual attention. Given an input image or video, these models compute a so-called saliency map that topographically encodes for saliency at every location in the image. Visual saliency models were shown to predict human visual performance for a number of psychophysical tasks and have a large number of applications. For example, in computer vision, saliency models were used for automated target detection in natural scenes, smart image compression, fast guidance of object recognition systems, or high-level scene analysis.
The key concept underlying this work is that by encouraging users to select password points that do not fall inside salient regions of the image, the security of gaze-based graphical passwords can be increased significantly. This is similar to the characteristics commonly required for text-based passwords, such as a minimum number of different alphanumeric or special characters.
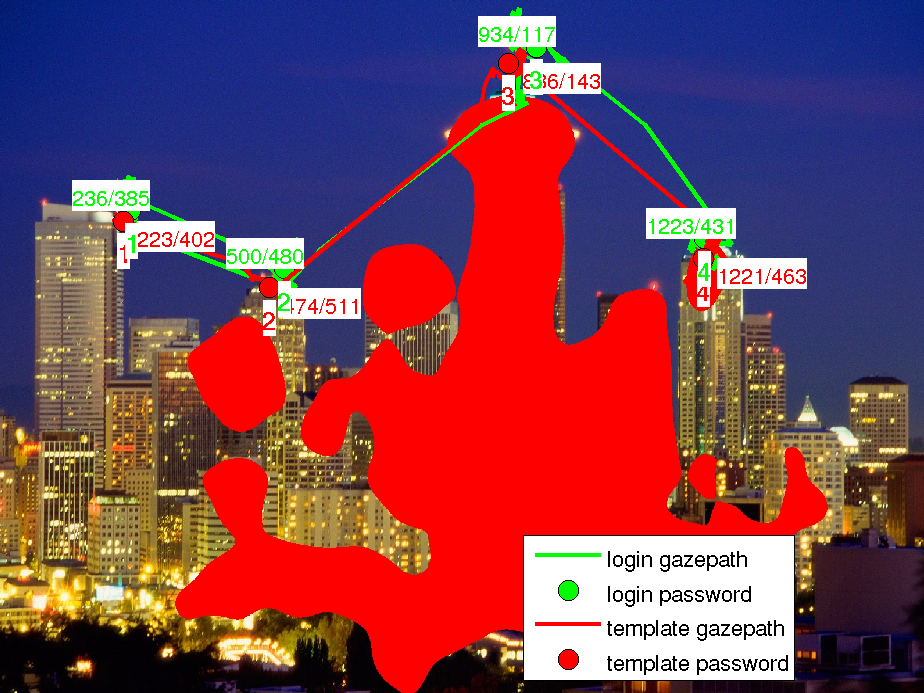
Figure 1a shows one of the normal login images used in this work. Because the penguins’ heads and feet are most likely to attract the user’s visual attention — as predicted by the visual saliency model — these parts are masked out in Figure 1b. In a real-world authentication system, such masked images would be shown to the user in selecting the initial password. During operation, such as for authentication at a public terminal, the same image but without a mask would be used instead.
Hypotheses
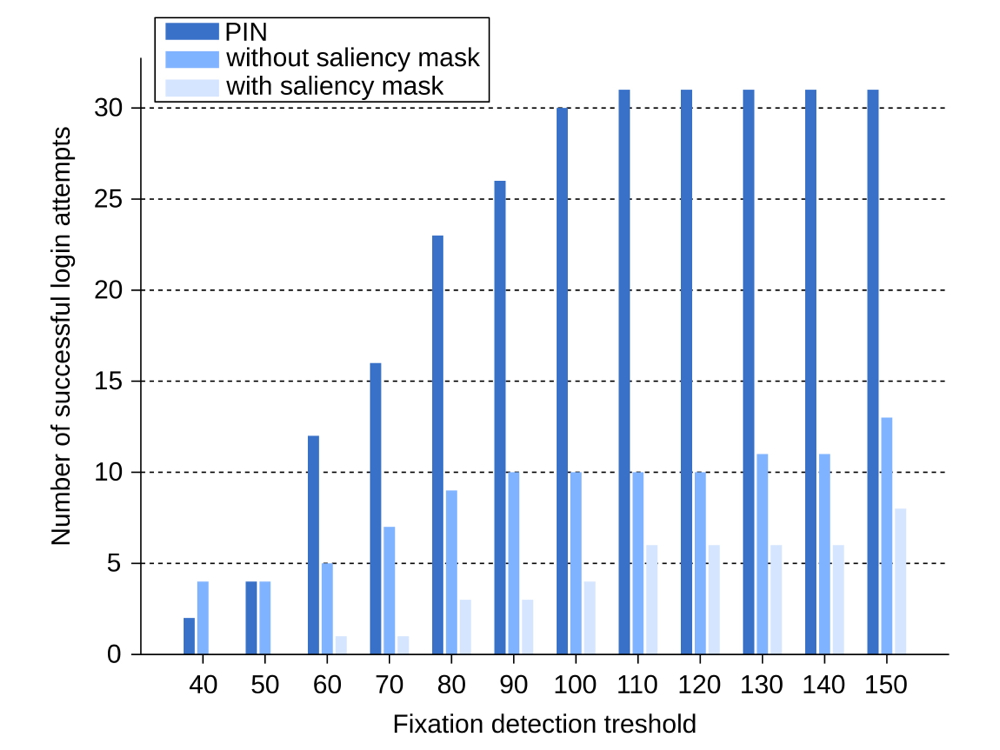
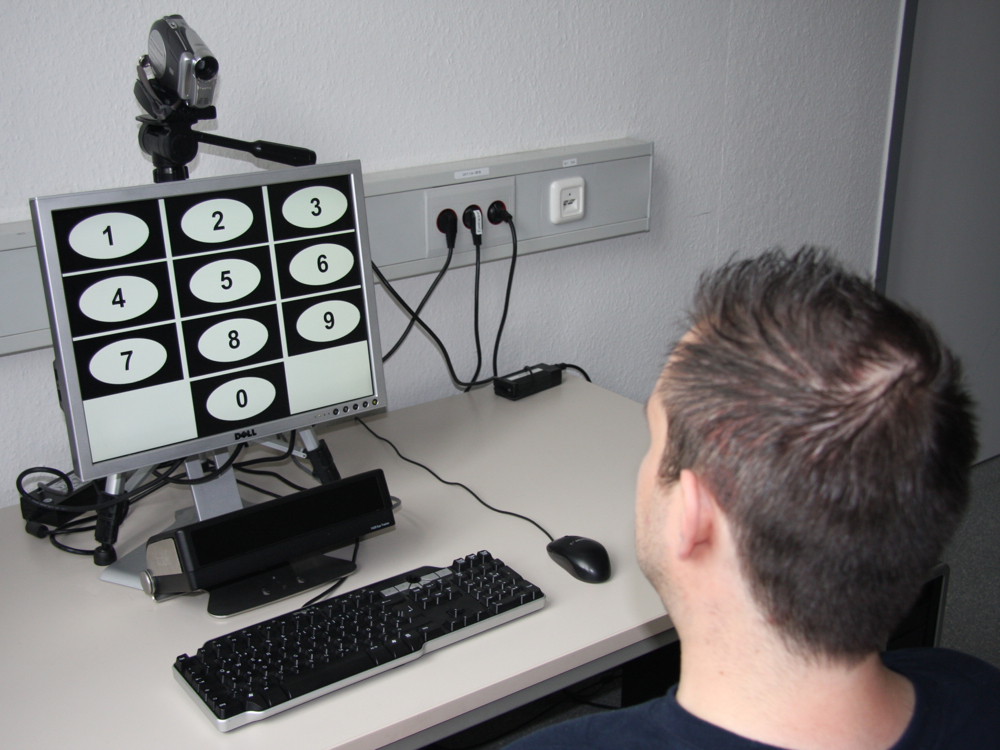
In this work our aim was to compare gaze-based graphical passwords with and without saliency masks. As a baseline, we opted to use gaze-based PIN entry, which is a common approach for implementing gaze-based graphical passwords~\cite{kumar07_soups}. More specifically, we investigated the following hypotheses:
- Gaze-based graphical passwords using several password points on an image are more secure, i.e. more difficult to attack, than gaze-based PIN entry.
- Saliency masks increase the strength of gaze-based graphical passwords and thus the system’s security.
Evaluation
The results of our study demonstrate that image-based graphical passwords are significantly more secure than PIN-based passwords, both in an actual attack and in terms of participant perception, hence verifying Hypothesis 1. Using computational models of visual attention to mask the most salient areas of the images does significantly increase security, compared to the standard image-based approach, hence verifying Hypothesis 2. In combination with the much larger theoretical password space, these results make saliency masks a promising means of increasing the security of gaze-based graphical passwords.
While image-based graphical passwords were perceived as significantly more secure than PIN-based passwords, the usability was rated lower by the participants in our study. Participants preferred image-based passwords for public terminals, while PIN-based passwords were preferred for mobile devices such as laptops and mobile phones. These responses may have been caused by the fact that participants could not imagine mobile devices being equipped with robust eye trackers in the near future. While currently, application domains are indeed mostly limited to ATMs or similar stationary systems, the advent of mobile eye trackers will pave the way for gaze-based authentication on smaller and thus more mobile devices.
A proper analysis of password memorability requires a long-term study and was therefore beyond the scope of this work. However, when we asked two pre-study participants to log in with their image-based passwords two days later (whom we did not ask to remember their passwords in the first place) they correctly remembered 14 out of 40 passwords (five images with and nine without a saliency mask). 13 of these image-based passwords were remembered by the pre-study participant who had selected the password points in the direction of reading, i.e. from left to right. While using such strategies seems to improve password memorability this may come at the cost of reduced security. We plan to investigate this trade-off between memorability and security in more detail in future work and particularly how password memorability can be improved without compromising security. In terms of security, it will also be interesting to see how saliency masks compare to other approaches, such as selecting password points on a sequence of images.
Finally, the study also reveals some of the issues researchers may face in the real-world implementation of gaze-based graphical passwords. Participants in our pre-study reported having used visual strategies for selecting their passwords points in the images. Two main-study participants noticed and exploited this behaviour by specifically looking for characteristic eye movement sequences such as in a vertical or horizontal direction. This suggests that, in addition to the saliency masks presented here, measures need to be taken to prevent users from choosing closely related password points (similar to preventing PINs like “1111” or “1234”). Additional user studies will be required to investigate whether users should be allowed to choose their own graphical passwords (and potentially the images as well), or whether both should be provided by the authentication system during registration. In the latter case, it would be useful to identify what defines such “good” passwords and images.
Images